
Data-Driven SEO: A Keyword Optimization Guide using Web Scraping & Co-occurrence Analysis (Graphext + Deepnote + Adwords) | Graphext
To improve our SEO, we built a data-driven method to analyze the content of top-ranking Google search results. Starting with a single search term, our technique uses web scraping + NLP techniques to find specific keywords that are already proven to boost the rank of similar pages.
If you already have an understanding of Search Engine Optimization (SEO), you’re probably aware of the importance of keywords. Keywords - dispersed throughout a webpage - are one of the many ways that Google understands how to list that page in its search results. Effective use of keywords makes your page more relevant to Google and its algorithms. Put simply, that helps people to find it.
In principle, it’s simple to come up with a list of keywords and add them to your article, post or webpage. But with billions of pages competing for Google’s top spots it is practically impossible to rank highly unless you pick the perfect keywords and relentlessly optimize your content.
It’s easy to spend all week tweaking an article to include different keywords and even easier to pay an agency to do it. The costs quickly add up and without a guarantee of success, it’s difficult to know if you are doing the right thing.
The Challenge
What if we could find out exactly which keywords + phrases are used by top-ranking websites and use them for ourselves?
Let’s go back to basics for a second. For every query put into Google, a sequence of URLs is returned. These are presented in order of relevance and relevancy is - in some way - determined by a page’s use of keywords. In theory, this means that the top 5-10 results should represent the most effective keyword usage for a given search query.
So if we get our hands on a list of the top-ranking URLs for a search query, we can scrape the text from each of these pages and analyze it. The idea is to take all of the text from a number of top-ranking pages and apply word co-occurrence analysis to highlight significant keywords.
In essence, this is reverse-engineering
relevant
and
effective
keyword strategies from
top-ranking websites
associated with specific search queries.
What do we need?
- 1x Blog Post / Article / Digital Content Piece (we’ll be optimizing this).
- 1x Initial search term.
- The ability to run a Deepnote (Python) notebook (we’re supplying the notebook).
What are we going to do?
- Use Google Adword Keyword Planner to get a list of search queries we want our article to be listed under.
- Use Python to retrieve the top 10 search result URLs for each of the search queries.
- Save this as a dataset with one URL per row.
- Upload the dataset to Graphext.
- (5 clicks) Use Graphext to scrape the text from each URL and model the co-occurrence of keywords in all this text.
- Find new, directly relevant keywords.
The Analysis (Sneak Peak)
We’ll be analyzing keywords from top-ranking websites related to search queries around ‘Keyword Optimization’. The analysis will focus on identifying important keywords found on these sites, associating them with other related keywords and considering how competitive they are.
This is the network of Keywords we’ll be building ...

Graph: A network of co-occuring keywords (scraped from top-ranking websites)
The Method
01. Use Adwords - Keyword Planner to Generate a List of Google Search Queries
To begin, we need to get a list of search queries. Pass an initial keyword to Google Adwords Keyword Planner and the tool will generate a list of associated words and phrases we can use as search queries. Here’s a helpful guide on setting up Keyword Planner from Backlinko.
Pick a short phrase that summarizes your page and use it to return a list of associated queries. For this article, we started with the term ‘keyword optimization’ - something that’s pretty close to the general theme of what we are talking about here.
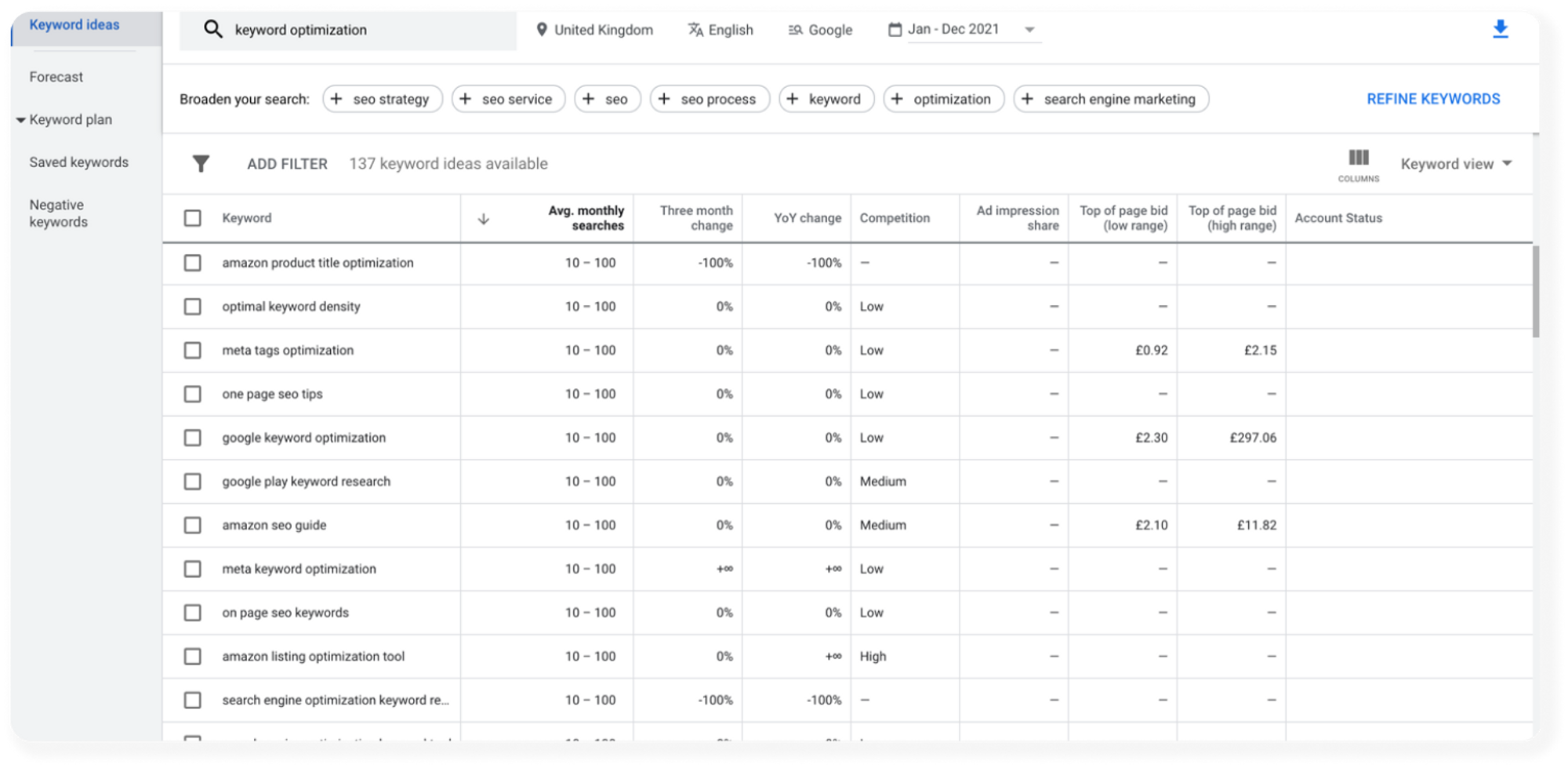
Keyword Planner will generate a table like the one below featuring some pretty useful information about the number of searches associated with each term. We’ll hold on to this but mainly we’re interested in the Keyword column.
Download the dataset to Google Sheets - we have to do a little cleaning before we move on.
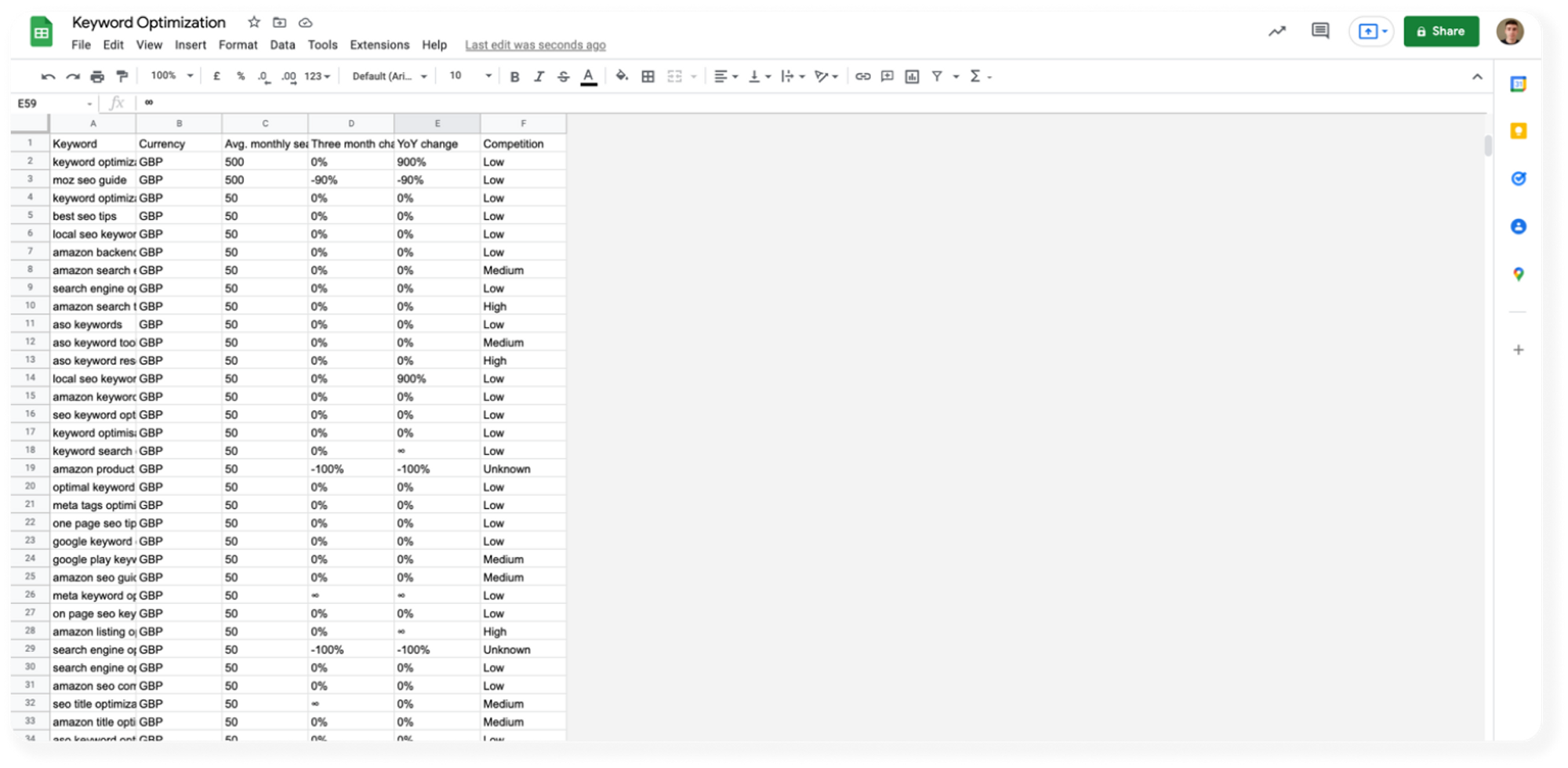
Annoyingly, the dataset has a title and a date range in the first two rows. Delete these two rows and remove columns G - AD (we don’t need any of this data). When you have a dataset that looks something like the one below, download the file again as a ‘.csv’ this time.
02. Use Python + Deepnote to Return a Dataset of Top Ranking URLs from a List of Google Search Queries
We’ve now got a dataset of queries that we can use to perform searches and retrieve our top-ranking URLs. The next bit of the technique uses a bit of Python inside a Deepnote notebook.
To get up and running - duplicate this project and upload the Keyword Planner dataset you just got from Google Sheets to the project workspace. Rename the file ‘KeywordPlannerDataset.csv’ so you don’t have to change any code whatsoever!
The notebook does two important things;
1. Performs a Google search for every query in the Keyword Planner dataset and returns the 10 top-ranking URLs for each query.
2. Transforms the dataset so each row represents 1 URL alongside the search query it was returned from and its ranking index.
Here’s the full notebook. Run it in full on Deepnote but make sure to duplicate the project first! The final step will save the transformed dataset as a new ‘.csv’ file in your Deepnote workspace. Download it.
03. Web Scraping & Keyword Co-Occurrence Analysis
With a dataset full of URLs, we can now plug in our data to Graphext and scrape the text from each URL at the same time as running our analysis on the text.
Upload the dataset to Graphext and choose Text > Word co-occurrence as the analysis type. This means that the analysis will model and highlight the co-occurring keywords found inside all of the URLs. We’ll end up with a network of linked keywords that frequently occur in the same section of text as one another.
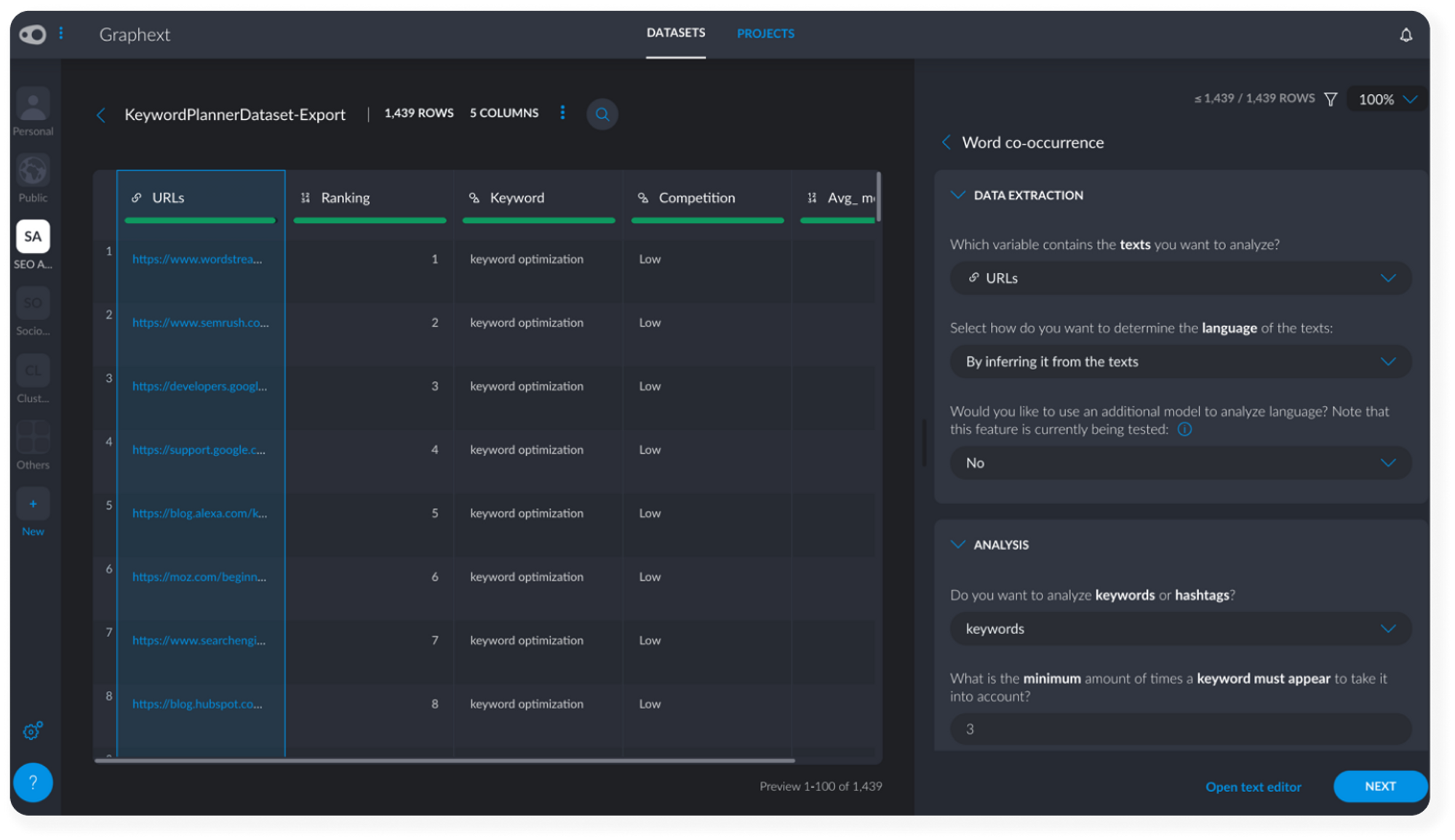
Set Up the Analysis (6 Clicks)
- Inside Text > Word co-occurrence, open the Data Extraction tab and make sure the URLs column is set to the text you want to analyze. Graphext will automatically scrape the text from the URLs.
- Open the Analysis tab and increase the number of times a keyword must appear to take it into account from 3 to 5. This means less frequent words won’t appear in our analysis.
- Click Next.
- Name your project.
- Click Execute.
Once the project is built, open it. We’re ready to start finding insights.
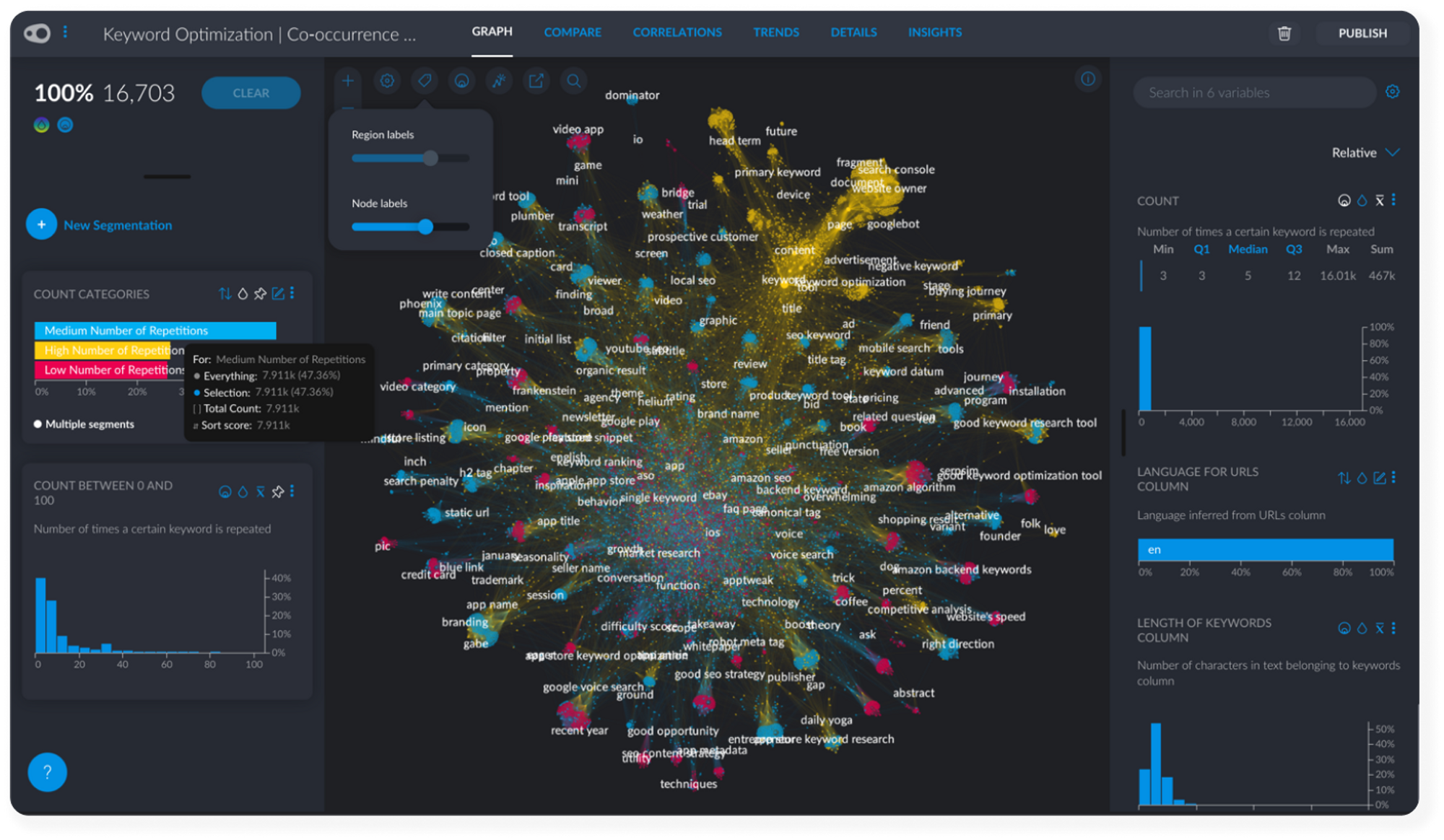
04. Finding Keywords Optimization Insights with Graphext
During the execution of the project, Graphext scraped each website in the dataset and collected its content. The project’s network is labelled with text extracted from these sites and each node in the network represents a value from the Keyword variable. Increase the labels using either the Graph Manager sidebar or the label slider at the top of the network.
Keywords are meaningful words appearing more than 5 times across all of the content we scraped. They are linked to one another based on their mutual occurrence inside the website’s text. Clicking on a keyword inside the Graph and selecting its neighbors shows which keywords are strongly associated with a specific term.
#1 Selecting Associated Keywords
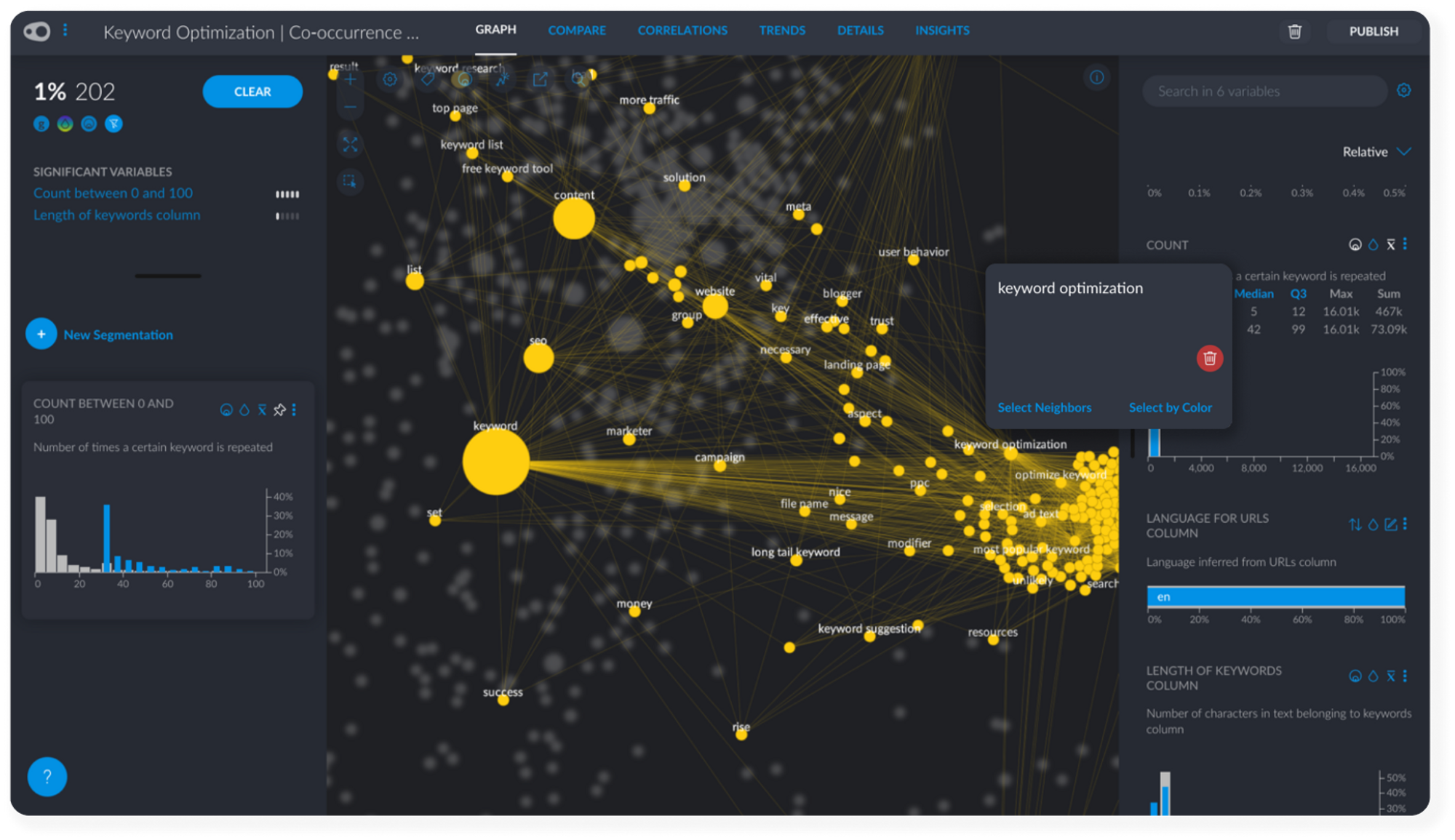
Count is a particularly useful variable that tells us how many times each word is repeated across all of our content. This is a pretty good indication of the popularity or competition surrounding each keyword. Keywords that appear many times are going to be difficult to rank for. Keywords that don't appear often might not be particularly relevant.
Find the Count variable and play around with the statistic filters associated with it. We can also zoom in on smaller numeric ranges, something that becomes particularly useful if we have outliers in the data - i.e keywords that appear many many times!
#2 Dealing with Keyword Frequency
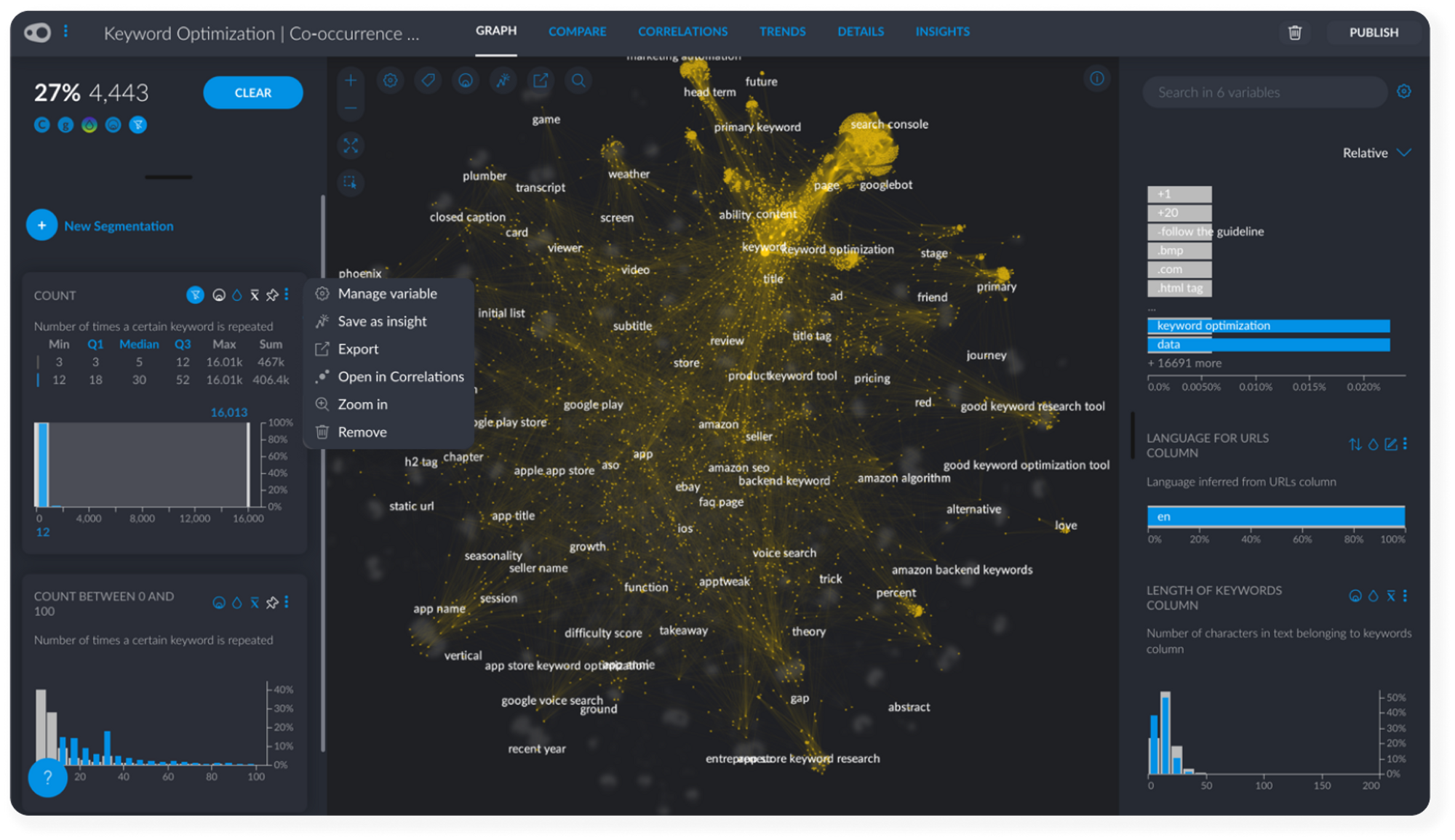
To make it easier to find insights related to the frequency of keywords across our content, create a manual segmentation that categorizes the numerical Count variable into High - Medium - Low values.
To do this, first create a new segmentation called something like Count Categories. Click on the Q1, Median and Q3 filters associated with Count to get automatic High, Medium and Low frequencies but make sure that you drag your filter to each extreme to include outliers in these segments! Add each segment by changing the filter range and adding a new segment to the Count Categories segmentation.
#3 Categorizing Keyword Frequency
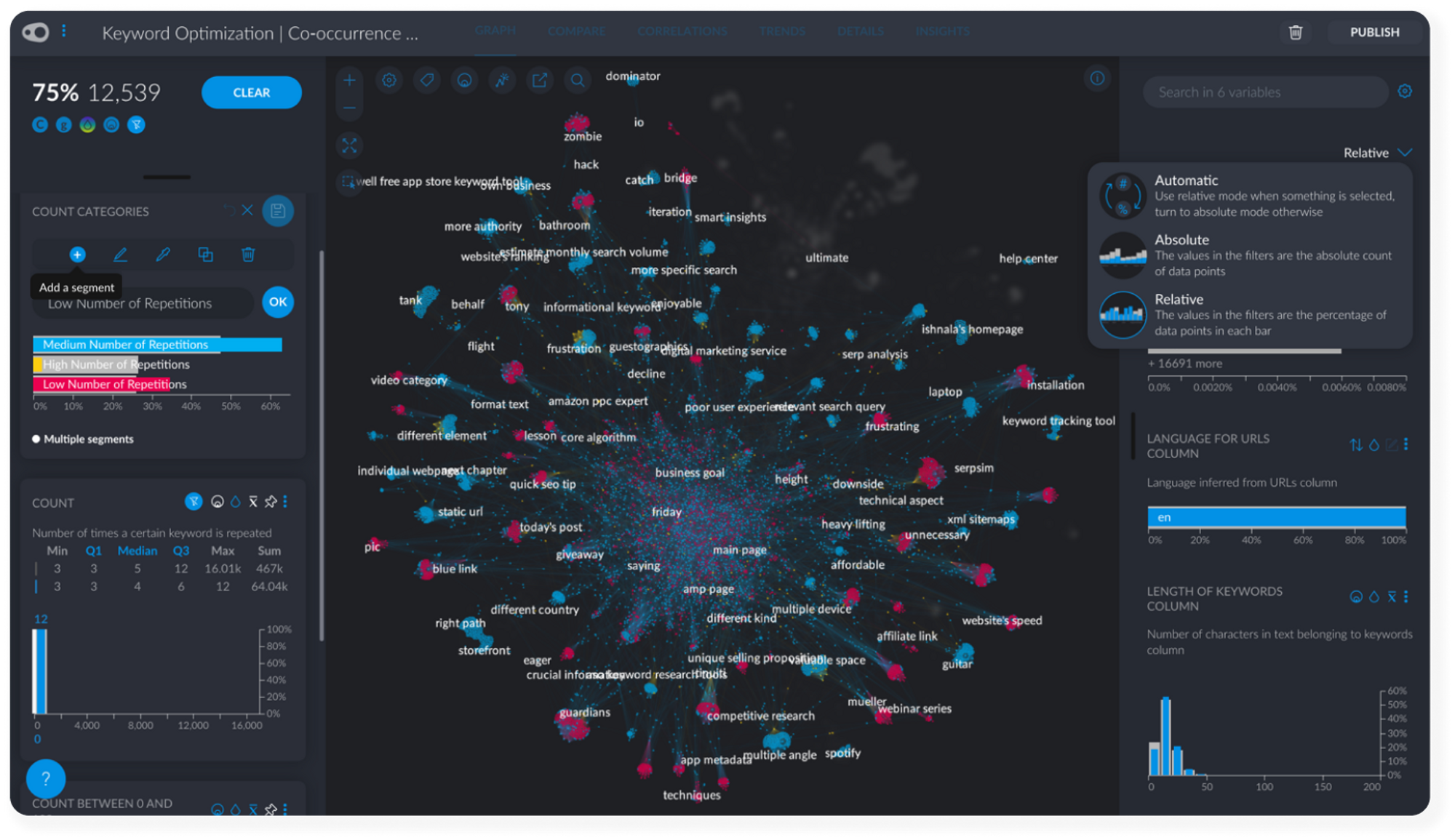
Get immediate insights by clicking on one keyword inside the network and selecting its neighbors. Neighbors are other keywords often found in mutual occurrence with a keyword.
On this page
- The Challenge
- The Method
- 01. Use Adwords - Keyword Planner to Generate a List of Google Search Queries
- 02. Use Python + Deepnote to Return a Dataset of Top Ranking URLs from a List of Google Search Queries
- 03. Web Scraping & Keyword Co-Occurrence Analysis
- Set Up the Analysis (6 Clicks)
- 04. Finding Keywords Optimization Insights with Graphext
On this page
- The Challenge
- The Method
- 01. Use Adwords - Keyword Planner to Generate a List of Google Search Queries
- 02. Use Python + Deepnote to Return a Dataset of Top Ranking URLs from a List of Google Search Queries
- 03. Web Scraping & Keyword Co-Occurrence Analysis
- Set Up the Analysis (6 Clicks)
- 04. Finding Keywords Optimization Insights with Graphext